Who will be the most talked-about celebrity before, during, and after the Super Bowl? 

Sunday, February 11, 2024
Taylor Swift and Data Analysis
Taylor Swift and Data Analysis. by Jerry Tuttle
She is an accomplished performer. songwriter, businesswoman, and philanthropist. I think she is very pretty. And those lips!
So what can a data analyst add to everything that has been said about her?
I was curious whether R could identify her lipstick color. I should preface this by saying I have some degree of color-challengedness, although I am not colorblind. I am also aware that you can Google something like "what lipstick shade does taylor swift use" and you will get many replies. But I am more interested in an answer like E41D4F. I do wonder if I could visit a cosmetics store and say, "I'd like to buy a lipstick for my wife. Do you have anything in E41D4F ?"
There are sites that take an image, allow you to hover over a particular point, and the site will attempt to identify the computer color. Here is one: RedKetchup But I want a more R-related approach. A note on computers and colors: A computer represents an image in units called pixels. Each pixel contains a combination of base sixteen numbers for red, green and blue. A base 16 number ranges from 0 through F. Each of red, green and blue is a two-digit base 16 number, so a full number is a six-digit base 16 number. There are 16^ 6 = 16,777,216 possible colors. E41D4F is one of those 16.8 million colors.
There are R packages that will take an image and identify the most frequent colors. I tried this with the image above, and I got unhelpful colors. This is because the image contains the background, her hair, her clothing, and lots of other things unrelated to her lips. If you think about it, the lips are really a small portion of a face anyway. So I need to narrow down the image to her lips.
I plotted the image on a rectangular grid, using the number of columns of the image file as the xlimit width, and the number of rows as the ylimit height. Then by trial and error I manually found the coordinates of a rectangle for the lips. The magick library allows you to crop an image, using this crop format:

The package colouR will then identify the most frequent colors. I found it necessary to save the cropped image to my computer and then read it back in because colouR would not accept it otherwise. The getTopCol command will extract the top colors by frequency. I assume it is counting frequency of hex color codes among the pixel elements. Here is a histogram of the result:

Really? I'm disappointed. Although I am color-challenged, this can't be right.
I have tried this with other photos of Taylor. I do get that she wears more than one lipstick color. I have also learned that with 16.8 million colors, perhaps the color is not identical on the entire lip - maybe some of you lipstick aficionados have always known this. All of these attempts have been somewhat unsatisfactory. There are too many colors on the graph that seem absolutely wrong, and no one color seems to really capture her shade, at least as I perceive it. Any suggestions from the R community?
No matter who you root for in the Super Bowl - go Taylor.
Here is my R code:
library(png)
library(ggplot2)
library(grid)
library(colouR)
library(magick)
xpos <- c(0,0,0)
ypos <- c(0,0,0)
df <- data.frame(xpos = xpos, ypos = ypos)
# downloaded from
# https://img.etimg.com/thumb/msid-100921419,width-300,height-225,imgsize-50890,resizemode-75/taylor-swift-mitchell-taebel-from-indiana-arrested-for-stalking-threatening-singer.jpg
img <- "C:/Users/Jerry/Desktop/R_files/taylor/taylor_swift.png"
img <- readPNG(img, native=TRUE)
height <- nrow(img) # 457
width <- ncol(img) # 584
img <- rasterGrob (img, interpolate = TRUE)
# print onto grid
ggplot(data = df,
aes(xpos, ypos)) +
xlim(0, width) + ylim(0, height) +
geom_blank() +
annotation_custom(img, xmin=0, xmax=width, ymin=0, ymax=height)
#############################################
# choose dimensions of subset rectangle
width <- 105
height <- 47
x1 <- 215 # from left
y1 <- 300 # from top
library(magick)
# must read in as magick object
img <- image_read('C:/Users/Jerry/Desktop/R_files/taylor/taylor_swift.png')
# print(img)
# crop format:
##############################################
# extract top colors of lips image
top10 <- colouR::getTopCol(path = "C:/Users/Jerry/Desktop/R_files/taylor/lips1.png",
# plot
# End
cropped_img <- image_crop(img, "105x47+215+300")
print(cropped_img) # lips only
image_write(cropped_img, path = "C:/Users/Jerry/Desktop/R_files/taylor/lips1.png", format = "png")
n = 10, avgCols = FALSE, exclude = FALSE)
top10
ggplot(top10, aes(x = hex, y = freq, , fill = hex)) +
geom_bar(stat = 'identity') +
scale_fill_manual(values = top10$hex) + # added this line based on suggestion
labs(title="Top 10 colors by frequency") +
xlab("HEX colour code") + ylab("Frequency") +
theme(
legend.position="NULL",
plot.title = element_text(size=15, face="bold"),
axis.title = element_text(size=15, face="bold"),
axis.text.x = element_text(angle = 45, hjust = 1, size=12, face="bold"))
##################################################################################
Tuesday, January 2, 2024
Using great circle distance to determine Twin Cities

- the cities must be at most 10 miles apart,
- each city must have at least 200,000 people, and
- the populations have to be within a ratio of 2:1.
I found https://simplemaps.com/data/us-cities has a dataset of 30,844 cities containing latitude, longitude, and population. However, when Minneapolis’ population came out as 2.9 million, Ben recognized that the population was shown for the broader metropolitan area, not the city proper. I got a second dataset of populations of city propers from https://www.census.gov/data/tables/time-series/demo/popest/2020s-total-cities-and-towns.html, I joined the two datasets, and I used the populations from the second database.
How do you measure the distance between two cities? This is not as simple a question as it sounds.
As a start, I used https://www.distancecalculator.net/ and entered two cities I am familiar with, New York, NY and Hoboken, NJ. That website calculated a distance of 2.39 miles, and it provided a map. The site further clarified that it used the great circle distance formula. So this raises two questions: How does it decide which two points to measure from, and what is a great circle distance?
Hoboken has an area of 1.97 square miles, so it probably doesn’t matter too much which point in Hoboken to use. New York City has an area of 472.43 square miles, so it does matter which point to use. It is not obvious which point it used, and it certainly did not use the closest point, but from other work, I believe it used City Hall or something close.

Latitude and longitude is a coordinate system to describe any point on the earth’s surface. Lines of latitude are horizontal lines parallel to the Equator, and represent how far north or south a point is from the Equator. Lines of longitude represent how far a point is east or west from a vertical line called the Prime Meridian that runs through Greenwich, England. Both latitude and longitude are measured in degrees, which are broken down into smaller units called minutes and seconds. For convenience they are also expressed in decimal degrees. If D is degrees, M is minutes, and S is seconds, then the conversion to decimal degree uses D + M/60 + S/3600.
When we use trig functions to calculate distances, we need to convert decimal degrees to radians by multiplying by π / 180. We also need to know the radius of the earth which is 3963.0 miles.
If point A is (lat1, long1) in decimals and point B is (lat2, long2) in decimals, then the distance formula d is the great-circle distance on a perfect sphere using the haversine distance formula, which is derived from principles of three-dimensional spherical trigonometry including the spherical law of cosines. A haversine of an angle θ is defined as hav(θ) = sin2(θ/2), and this concept is used in the derivation.
d = ACOS(SIN(PI()*[Lat_start]/180.0)*SIN(PI()*[Lat_end]/180.0)+COS(PI()*[Lat_start]/180.0) *COS(PI()*[Lat_end]/180.0)*COS(PI()*[Long_start]/180.0-PI()*[Long_end]/180.0))*3963
As I mentioned, I used https://simplemaps.com/data/us-cities which contains cities with their latitude and longitude, and I applied the above distance formulas to pairs of cities. But I was still curious about the choice of a latitude and longitude for a particular city. That file lists New York City as (40.6943, -73.9249). Another website that finds a street address from a decimal latitude and longitude, https://www.mapdevelopers.com/reverse_geocode_tool.php , lists the address of (40.6943, -73.9249) as 871 Bushwick Avenue, Brooklyn, which is some distance from City Hall, but does not appear to be the centroid of New York City either. Wikipedia's choice of latitude and longitude for New York City is 42 Park Row which is close to City Hall.
The following map from https://www.mapdevelopers.com/reverse_geocode_tool.php?lat=40.694300&lng=-73.924900&zoom=12 shows the approximate location of 871 Bushwick Avenue, Brooklyn.


Of these pairs, I actually like Hialeah and Miami as the true twin cities. Besides meeting the original three criteria, they both share the same large ethnic population and they share a public transportation system.
Wikipedia has a much larger list of twin cities https://en.wikipedia.org/wiki/Twin_cities, but they did not necessarily use Ben Olin's three criteria. Also, Ben's problem is for US cities only, and Wikipedia has several pairs of Canada-US and Mexico-US cities that I had not thought about.
Here is the R code I used:
df1 <- read.csv("https://raw.githubusercontent.com/fcas80/jt_files/main/uscities.csv")
df1 <- subset(df1, select = c(city, lat, lng, state_name))
n1 <- nrow(df1) # 30844
library("readxl")
df2 <- read_excel("https://raw.githubusercontent.com/fcas80/jt_files/main/censuspop.xlsx", mode = "wb", skip = 3)
df2 <- df2[ -c(1,4:6) ]
colnames(df2) <- c("city", "pop")
# city appears as format Los Angeles city, California
df2$state <- gsub(".*\\, ", "", df2$city) # extract state: everything after comma blank
df2$city <- gsub("\\,.*", "", df2$city) # extract everything before comma
df2$city <- gsub(" city*", "", df2$city) # delete: blank city
df = merge(x=df1, y=df2, by="city",all=TRUE)
df <- na.omit(df)
df <- df[df$pop >= 200000, ]
df <- df[df$state_name == df$state, ] # delete improper merge same city in 2 states
df <- subset(df, select = -c(state_name, state))
n <- nrow(df) # 112
kount <- 1
df11 <- data.frame()
for (i in 1:n){
Lat_start <- df[i,2]
Long_start <- df[i,3]
for (j in 1:n){
Lat_end <- df[j,2]
Long_end <- df[j,3]
dist_miles <- acos(sin(pi*(Lat_start)/180.0)*sin(pi*(Lat_end)/180.0)+
cos(pi*(Lat_start)/180.0)*cos(pi*(Lat_end)/180.0)*cos(pi*
(Long_start)/180.0-pi*(Long_end)/180.0))*3963
cos(pi*(Lat_start)/180.0)*cos(pi*(Lat_end)/180.0)*cos(pi*(Long_start)/180.0-pi*
(Long_end)/180.0))*3963
dist_miles <- round(dist_miles, 0)
pop_ratio <- round(max(df[i,4]/df[j,4], df[j,4]/df[i,4]),1)
if (df[i,1] != df[j,1] & dist_miles > 0 & dist_miles <= 10 & pop_ratio <= 2){
df11[kount,1] <- df[i,1]
df11[kount,2] <- df[j,1]
df11[kount,3] <- dist_miles
df11[kount,4] <- df[i,4]
df11[kount,5] <- df[j,4]
df11[kount,6] <- pop_ratio
df11[kount,7] <- df[i,4] + df[j,4]
kount <- kount + 1
}
}
}
colnames(df11) <- c("City1", "City2", "Dist", "Pop1", "Pop2", "Ratio", "TotPop")
df11 <- df11[!duplicated(df11$TotPop), ] # remove duplicates
df11 <- df11[ -c(7) ]
df11 <- data.frame(df11, row.names = NULL) # renumber rows consecutively
df11
Sunday, December 3, 2023
Ten Lords-a-Leaping
Just what is a lord-a-leaping? Well, what is a lord? A lord is a title of nobility, usually inherited, that exists in the UK and other countries. And those lords like to leap, especially during the twelve days of Christmas. 



The song the Twelve Days of Christmas is a well-known Christmas song, whose earliest known publication was in London in 1780. There are various versions of the lyrics, various melodies, and meanings of the gifts. As usual, this is all nicely summarized in Wikipedia https://en.wikipedia.org/wiki/The_Twelve_Days_of_Christmas_(song) .
PNC Bank, one of the largest banks in the US, has been calculating the prices of the twelve gifts given by my true love since 1984, and has trademarked its PNC Christmas Price Index ® . Two senior executives at PNC calculate the prices, and many of the details are available at https://www.pnc.com/en/about-pnc/topics/pnc-christmas-price-index.html#about , especially in their FAQ. In particular, they note that the price of services has generally increased while the price of goods has slowed. The price index is a humorous proxy for the general cost of inflation.
On day one there was 1 gift (the partridge). On day two there were 3 gifts (2 doves + 1 partridge). On day three there were 6 gifts (3 hens + 2 doves + 1 partridge). On day twelve there were 78 gifts, and 78 is the sum of the first 12 natural numbers, whose general formula Σn = n(n+1)/2 was known by Gauss in the 1700’s.
The cumulative number of gifts is 1 + 3 + 6 + … + 78, whose sum is 364. (One fewer than the number of days in a year. Coincidence?) Each of these numbers is called a Triangular number Ti , and the general formula of their sum is Σ Ti = n(n+1)(n+2)/6.

The PNC Christmas Price Index ®, or the Total Cost of Christmas reflects the total cost of the 78 gifts: one set of each of the gifts. For 2023 that cost is $46,729.86, versus $45,523.33 in 2022, a change of + 2.7%. The prior year’s change was 10.5%. The largest individual item in the index is not the five gold rings as I had thought ($1,245), but rather those leaping lords ($14,539, up 4.0%), followed by the swimming swans ($13,125 and unchanged for many years).
PNC also calculates the True Cost of Christmas, which is the cost of 364 gifts. For 2023 that cost is $201,972.66, a change of 2.5% over a year ago.
And PNC calculates a core index excluding the swans, which some time ago had been the most volatile item, and also an e-commerce index buying all items online.
The overall Bureau of Labor Statistics CPI for All Urban Consumers (CPI-U) increased 3.2% for twelve months ending October 2023. October is the closest month for CPI-U to the PNC data. CPI-U of course is based on a broad market basket of goods including food, energy, medical care, housing, transportation, etc., which are not the gifts given in the song, but CPI-U is a common measure of inflation. The PNC index is based on a very specific twelve items and is heavily weighted toward the lords and the swans.
The PNC website contains detailed information on its calculations, but it does not contain historical information on CPI-U. I used twelve-month October historical CPI-U percent changes from https://www.bls.gov/regions/mid-atlantic/data/consumerpriceindexhistorical_us_table.htm . Then I graphed the percentage changes of the PNC Christmas Price Index® , the PNC True Cost of Christmas index, and the CPI.
With such a small number of items, the two PNC indices fluctuate drastically. 2014 reflects a one-time increase in the cost of the swans. 2020 was the unusual year during the pandemic when some of the gifts (including the lords!) were unavailable and so the cost that year was zero. The two PNC indices were fairly close to CPI-U for five years starting in 2015 and again for 2022 and 2023. Maybe these PNC indices are pretty good.

PNC uses the Philadelphia Ballet to calculate the cost of the lords-a-leaping.
Here is the R code I used:
library(readxl)
library(ggplot2)
df1 <- read_excel("C:/Users/Jerry/Desktop/R_files/xmas.xlsx", sheet = 1)
df2 <- read_excel("C:/Users/Jerry/Desktop/R_files/xmas.xlsx", sheet = 2)
cpi <- round(df2$Percent_change,3)
df1 <- df1[c(3:13)]
year <- as.numeric(colnames(df1)[2:11])
total_cost_dollars <- colSums(df1)
total_cost_index <- vector()
true_cost_dollars <- vector()
true_cost_index <- vector()
for(i in 1:length(total_cost_dollars)){
true_cost_dollars[i] <- 12*df1[1,i] + 11*df1[2,i] + 10*df1[3,i] + 9*df1[4,i] + 8*df1[5,i] +
7*df1[6,i] + 6*df1[7,i] + 5*df1[8,i] + 4*df1[9,i] + 3*df1[10,i] + 2*df1[11,i] + 1*df1[12,i]
}
true_cost_dollars <- unlist(true_cost_dollars)
for(i in 1:length(total_cost_dollars) - 1){
total_cost_index[i] <- round(100*(total_cost_dollars[i+1]/total_cost_dollars[i] - 1),1)
true_cost_index[i] <- round(100*(true_cost_dollars[i+1]/true_cost_dollars[i] - 1),1)
}
df <- data.frame(cbind(year, total_cost_index, true_cost_index, cpi))
colors <- c("total_cost_index" = "red", "true_cost_index" = "navy", "cpi" = "grey")
ggplot(df, aes(x=year)) +
geom_line(aes(y=total_cost_index, color="total_cost_index")) +
geom_line(aes(y=true_cost_index, color="true_cost_index"))
geom_line(aes(y=cpi, color="cpi")) +
labs(title = "12 Days of Christmas", x = "Year", y = "Percent change", color = "Legend") +
scale_color_manual(values = colors) +
# scale_y_continuous(labels = scales::percent_format(scale = 1, prefix = "", suffix = "%")) +
theme(
legend.position="right",
plot.title = element_text(size=15, face="bold"),
axis.title = element_text(size=15, face="bold"),
axis.text = element_text(size=15, face="bold"),
legend.title = element_text(size=15, face="bold"),
legend.text = element_text(size=15, face="bold"))
Tuesday, August 8, 2023
Black hole word numbers in multiple languages

First, a review with English words. Every English word gets you to the same black hole number as you count the number of letters in the word and then successively count the number of letters in the resulting word number. That black hole is at four. Once you get to four, you are stuck and can't get out. Here is an example.
The word hippopotomonstrosesquippedaliophobia (fear of long words) has 36 letters.
The word thirtysix has nine letters.
The word nine has four letters.
The word four has four letters.
Here are some more English words, with their word number length counting sequence. I found a long list of English words, so this list is truly a random sample. (For the other languages, I could not find a nice long list, so the words are not random but rather a convenience sample.)
miscognizable thirteen eight five four
harvestry nine four
geopolitist eleven six three five four
jessed six three five four
pardonee eight five four
whitfield nine four
ghazal six three five four
morphophonemically eighteen eight five four
calonectria eleven six three five four
conceptiveness fourteen eight five four
Every German word also gets you to the same black hole number: vier.
handschuh neun vier
flugzeug acht vier
staubsauger elf drei vier
waschmaschine dreizehn acht vier
haustürschlüssel sechszehn neun vier
lächeln sieben sechs funf vier
geutscher neun vier
danke funf vier
morgen sechs funf vier
tee drei vier
torschlusspanik funfzehn acht vier
In Hebrew, where there is the complication that letters are written from right to left, there are two black hole numbers: ארבע and שלש . Below, the rightmost word is the word whose letters are first counted, and the subsequent counting is from right to left.
פירת ארבע
אורתודוקסית אחדעשר שש שתים ארבע
קומוניסטית עשר שלש
ומועמדויות עשר שלש
עיתונות שבע שלש
ארוך ארבע
שלה שלש
כך שתים ארבע
לראות חמש שלש
להסתכל שש שתים ארבע
In Spanish there is a black hole at cinco. However, unlike the previous languages that had a black hole where you are stuck and can't get out, Spanish also has some words where you oscillate back and forth between two numbers but never really fall into a hole. These two Spanish numbers are seis and cuatro.
montaña ocho cuatro seis cuatro seis cuatro seis cuatro seis cuatro
Iglesia siete cinco
computadora once cuatro seis cuatro seis cuatro seis cuatro seis cuatro
oficina siete cinco
preguntar nueve cinco
entender ocho cuatro seis cuatro seis cuatro seis cuatro seis cuatro
hermosa siete cinco
asombroso nueve cinco
perezoso ocho cuatro seis cuatro seis cuatro seis cuatro seis cuatro
somnoliento doce cuatro seis cuatro seis cuatro seis cuatro seis cuatro
saludable nueve cinco
This is reminiscent of some numerical algorithms that oscillate and never converge. For example, if f(x) = x3 -2*x + 2 and x0 = 1, which has a single root at approximately -1.769, Newton-Raphson approximations will oscillate between x = 0 and x = 1, and f(x) = 1 and f(x) = 2 and never find the root. You can see from the first graph that the oscillation occurs at the wrong section of the curve.

Here is the R code I used:
####################################################
# Try hippopotomonstrosesquippedaliophobia (fear of long words) which has 36 letters.
library(english)
x <- "hippopotomonstrosesquippedaliophobia"
y <- -99 # Initialize y
while(y != "four"){
y <- nchar(x)
y <- as.character(english(y)) # Spell out an integer as a word
if (grepl('-', y, fixed = TRUE)) y <- gsub('-', '', y) # delete hyphen
print(c(x,y))
x <- y
}
####################################################
# Try ten random English words
library(english)
library(wordcloud)
set.seed(123)
words <- read.table("https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt")
original <- sample(words$V1, 10, replace = FALSE)
# original <- c(
"miscognizable","harvestry","geopolitist","jessed","pardonee","whitfield","ghazal","morphophonemically",
"calonectria","conceptiveness")
wordcloud(word=original, random.order = TRUE, colors=c("red","blue","darkgreen","brown","black","red",
"blue","darkgreen","navy","black"), ordered.colors=TRUE,, scale=c(3,7))
rm(words) # free up memory
for (i in 1:10){
x <- original
y <- vector()
y[1] <- "dummy" # Initialize y
for (j in 1:100){
c <- nchar(x[i])
c <- as.character(english(c)) # Spell out an integer as a word
if (grepl('-', c, fixed = TRUE)) y[j] <- gsub('-', '', c) else y[j] <- c # delete hyphen
x[i] <- y[j]
if (y[j] == "four") {
break
}
}
cat(c(original[i], "\t", y), "\n")
}
####################################################
# Try 10 Hebrew words
original <- c("פירת", "אורתודוקסית", "קומוניסטית", "ומועמדויות", "עיתונות", "ארוך", "שלה", "כך", "לראות", "להסתכל" )
numbs <-
c("אחת", "שתים", "שלש", "ארבע", "חמש", "שש", "שבע", "שמונה", "תשע", "עשר","אחד עשר","שתיים עשרה","שלוש עשרה","ארבעה עשר","חמש עשרה","שש עשרה","שבע עשרה","שמונה עשרה","תשע עשרה","עשרים")
for (i in 1:10){
x <- original
y <- vector()
for (j in 1:10){
c <- nchar(x[i])
y[j] <- numbs[c]
if (grepl(' ', y[j], fixed = TRUE)) y[j] <- gsub(' ', '', y[j]) # delete space
x[i] <- y[j]
if (y[j] == "ארבע" | y[j] == "שלש") {
break
}
}
cat(c(original[i], "\t", y), "\n")
}
####################################################
# Try 11 Spanish words; however, infinite oscillation without convergence at cuatro and seis
x <- c("montaña","Iglesia","computadora","oficina","preguntar","entender","hermosa","asombroso","perezoso"," somnoliento","saludable")
numbs <- c(
"uno", "dos", "tres", "cuatro", "cinco", "seis", "siete", "ocho",
"nueve", "diez", "once", "doce", "trece", "catorce", "quince",
"dieciséis", "diecisiete", "dieciocho", "diecinueve", "veinte")
original <- x
for (i in 1:11){
y <- vector()
for (j in 1:10){
c <- nchar(x[i])
y[j] <- numbs[c]
x[i] <- y[j]
if (y[j] == "cinco") {
break
}
}
cat(c(original[i], "\t", y), "\n")
}
####################################################
# Try 11 German words
x <- c("handschuh","flugzeug","staubsauger","waschmaschine","haustürschlüssel","lächeln","geutscher", "danke", "morgen","tee","torschlusspanik")
numbs <- c(
"eins","zwei","drei","vier","funf","sechs","sieben","acht","neun","zehn",
"elf","zwolf","dreizehn","vierzehn","funfzehn","sechszehn","siebzehn",
"achtzehn","neunzehn"," zwanzig")
original <- x
for (i in 1:11){
y <- vector()
for (j in 1:10){
c <- nchar(x[i])
y[j] <- numbs[c]
x[i] <- y[j]
if (y[j] == "vier") {
break
}
}
cat(c(original[i], "\t", y), "\n")
}
####################################################
# Newton-Raphson: x(n+1) = xn - f(xn) / f ' (xn)
# f(x) = x^3 -2*x + 2
# f ' (x) = 3*(x^2) - 2
par(mfrow = c(1, 2))
# quick plot to choose initial value
x<- seq(from=-5, to=5, .001)
y <- x^3 - 2*x + 2
plot(x,y, main="f(x) = x^3 -2*x + 2", xlab="x", ylab="y", col="red", ylim=c(-2,4), cex.main = 3)
axis(side = 1, font = 2, cex.axis = 2)
axis(side = 2, font = 2, cex.axis = 2)
abline(h=0)
# Newton-Raphson
x <- vector()
f <- vector()
x_new <- 1 # initial guess
for (n in 1:10){
x[n] <- x_new
f[n] <- (x[n])^3 - 2*x[n] + 2
fprime <- 3 * (x[n])^2 -2 # manual derivative calculation
x_new <- x[n] - f[n]/fprime
if ( (abs(x[n] - x_new)/x[n]) < .00005 ){break}
}
df <- data.frame(cbind(x,f))
df <- head(df, 10)
df
plot(df$x, df$f, pch = 16, cex = 2, main="Sequence of N-R points", xlab="x", ylab="y", cex.main = 3)
for (i in 1:nrow(df)){
arrows(x0 = x[i], y0 = f[i], x1 = x[i+1], y1 = f[i+1], col="blue")
}
axis(side = 1, font = 2, cex.axis = 2)
axis(side = 2, font = 2, cex.axis = 2)
abline(h=0)
dev.off() # reset par
Wednesday, July 26, 2023
Barbie and math

If the original Barbie doll were an actual woman, she would be 5'9" tall, have a 39-inch bust, 18-inch waist, 33-inch hips, a size 3 shoe, a weight of 110 pounds, a BMI of 16.24, and perhaps would be anorexic. (Click anorexic for the source of those measurements.) Obviously these measurements are unrealistic and send a harmful message to children. But there's a lot more to Barbie and math.
In 1992 the infamous talking Barbie included the phrase "Math class is tough!" which was bad enough, but it was ironically misreported by the press as "Math is hard." Neither is the message we want to give to children. This immediately drew protests from the National Council of Teachers of Mathematics, the American Association of University Women, and others. Mattel removed the phrase from future dolls, and the original is now a collector's item.
Perhaps embarrassed by this experience, subsequently Barbie put her life on the line in a high school project Barbie Bungie to help students learn algebra, physics, and statistics. This is a hands-on experiment attaching Barbie to a thick rubber band, dropping her from a height, measuring the distance of a jump and the time to descend, and then estimating the line of best fit. NCTM has a suggested lesson on this.
But I want to spend the remainder of this article talking about Barbie and the mathematics of her facial beauty.
The ancient Greeks discovered a particular number called the Golden Ratio, denoted by Greek letter Φ (phi), that has many interesting mathematical properties, apppears in some patterns of nature, and is considered by many to be asthetically pleasing. The Golden Ratio results from finding the point on a line segment that splits the segement into two smaller segments with lengths a and b, such that (a + b)/a = a/b.

That ratio a/b is the Golden Ratio, Φ. With a little algebra, Φ = (1 + √5)/2 , which is an irrational number so it has an infinite non-repeating decimal, and rounded to three decimal places is 1.618.
Renaissance artists, plastic surgeons, and makeup artists are among those who use Golden Ratios in various ways with faces to create ideally proportioned faces. Gary Meisner has wriiren extensively on the Golden Ratio, and he believes there are over 20 different ways that the Golden Ratio shows up in human faces and that “the Golden Ratio is also found very commonly in beautiful models of today across all ethnic groups. Biostatistican professor Dr. Kendra Schmid and her colleagues performed various measures of many faces. They began with 17 potential Golden Ratios, and they decided only six of these ratios were predictors of facial attractiveness. See Schmid.
This takes us to Barbie. I attempted to measure these six ratios on a picture of Barbie (the doll, not the actress). There are many pictures of Barbie, she does enjoy experimenting with different hairstyles, and I had to find one with a hairstyle that gave me the best chance of measuring her from her hairline and also between her ears. The measurement is not exact for many reasons, and because we are using a two-dimensional photo of a three-dimensional object there is certainly some loss of accuracy. Nevertheless, here are the results:
| Face length / Face Width | 1.07560 |
| Mouth width / Interocular distance | 1.93750 |
| Mouth width / Nose width | 1.97872 |
| Lips to chin / Interocular | 1.54167 |
| Lips to chin / Nose width | 1.574447 |
| Ear length / Nose width | 1.57447 |
| Average | 1.61374 |
| % Deviation from Φ | - 0.27% |
I have repeated this measurement process with celebrity faces that I think most people would consider attractive. (This is the sort of thing I would do.) Many celebrities have close phi-ratios such as Scarlett Johansson, Ryan Gosling, Brad Pitt, and Lupita Nyong'o, but none are as close to Φ as Barbie. Some celebrity faces that I think most people would consider attractive did not score well, but possibly this is due to the measurement difficulties I discussed above.
However, I think the conclusion is clear: Barbie is an ideal beauty, using the Golden Ratio as a standard. But as they say, beauty is in the Phi of the beholder.
R Programming Notes:
I attempted doing the facial measurements in R. A tip of the hat to @technocrat who helped me with some of the code. With his help, I was able to read the Barbie graphic image into R and add the image onto a ggplot with coordinate axes. I then attempted to find the coordinates of the line segments corresponding to the 6 ratios and to calculate the ratios of the appropriate line segments. See the image below with the line segments. However, drawing these segments and finding the coordinates turned out to be too crude, and the results were unreliable. I include the code below as a reference for superimposing a graphic onto a ggplot. However, I redid the measurements with more precise software using Gary Meisner's software PhiMatrix , and the results in the table above are based on that software. Nevertheless, here is the R code I used:

library(magick)
library(grid)
# Read the barbie image
barbie <- image_read("barbie.jpg")
barbie <- image_scale(barbie, "300")
# Create a data frame for the line segments
line_data <- data.frame(
x1 = c(100, 150, 140, 138, 210, 138, 150),
y1 = c(290, 355, 302, 260, 280, 260, 275),
x2 = c(210, 150, 167, 170, 210, 138, 155),
y2 = c(290, 235, 302, 260, 310, 235, 275)
)
rownames(line_data) <- c("Face_width","Face_length","Interocular", "Mouth_width", "Lips_2_chin", "Ear_length", "Nose_width" )
# Create a ggplot
p <- ggplot() +
geom_blank() +
theme_minimal() +
theme(
plot.background = element_blank(),
panel.grid = element_blank()
) +
coord_fixed(xlim = c(0, 300), ylim = c(0, 606)) +
xlab("") +
ylab("") +
scale_x_continuous(breaks = seq(0, 300, by = 50)) +
scale_y_continuous(breaks = seq(0, 606, by = 50)) +
geom_hline(yintercept = seq(0, 606, by = 50), linetype = "dotted", color = "gray") +
geom_vline(xintercept = seq(0, 300, by = 50), linetype = "dotted", color = "gray")
# Convert the barbie image to a raster object
barbie_raster <- as.raster(barbie)
# Add the barbie image to the ggplot2 plot
p <- p +
annotation_custom(
grob = rasterGrob(barbie_raster),
xmin = 0, xmax = 300,
ymin = 0, ymax = 606
)
# Add the lines to the plot
p <- p +
geom_segment(
data = line_data,
aes(x = x1, y = y1, xend = x2, yend = y2),
color = c("red", "blue", "black", "red", "navy", "black","navy"),
size = 1.5
)
# Display the plot
print(p)
rownames(line_data) <- c("Face_width","Face_length","Interocular", "Mouth_width", "Lips_2_chin", "Ear_length", "Nose_width" )
d <- vector()
d <- sqrt((line_data$x1 - line_data$x2)^2 + (line_data$y1 - line_data$y2)^2)
Face_width <- d[1]
Face_length <- d[2]
Interocular <- d[3]
Mouth_width <- d[4]
Lips_2_chin <- d[5]
Ear_length <- d[6]
Nose_width <- d[7]
r <- vector()
r[1] <- Face_length / Face_width
r[2] <- Mouth_width / Interocular
r[3] <- Mouth_width / Nose_width
r[4] <- Lips_2_chin / Interocular
r[5] <- Lips_2_chin / Nose_width
r[6] <- Ear_length / Nose_width
m <- mean(r)
phi <- (1 + sqrt(5))/2
percent_deviation <- (m - phi)/phi
Saturday, July 22, 2023
Happy Pi Approximation Day

π Is defined as the ratio of a circle’s circumference to its diameter. π Is an irrational number (it cannot be expressed as the ratio of two integers), and it has an infinite number of non-repeating digits. Approximations of π date back to ancient civilizations and continue today as people compete to calculate π to billions of decimal places on supercomputers.
The 22/7 approximation only matches π to the second digit after the decimal place, 3.14, and 22/7 is greater than π, a fact known by Archimedes. The error in the approximation is only about 0.04%, which is close enough for most of us.
People also compete in the number of decimal places they can recite by memory such as using mnemonic techniques with words, where the length of each word represents a digit of π . There are many creative π mnemonics , but I am content to remember the 15 word "How I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."
A quite impressive feat is Apu from the Simpsons who claimed to be able to recite 40,000 digits of π, and proved it by correctly stating that the 40,000th digit is 1. Apu
The R computer language carries 15 or 16 digits. That seems like enough. A NASA engineer says he can’t think of a practical application that would require more than 15 digits of π . NASA
π appears in many areas of math besides geometry and trigonometry. It is hidden away in statistics where the probability density function formula of the normal curve has a √(2π) term in the denominator to get the integral equal to 1, and elsewhere in other branches of math.
Happy Pi Approximation Day.
Here is some R code:
library(dplyr)
library(tidytext)
# compare 15 digits of 22/7 to pi
print(22/7, digits=15)
print(pi, digits=15)
# count word length & number of words in this mnemonic
textfile <- c("How I need a drink",
"alcoholic of course",
"after the heavy lectures involving quantum mechanics.")
df<-data.frame(line=1:length(textfile), text=textfile)
df_words <- df %>% unnest_tokens(word, text) %>% mutate(word_length = nchar(word))
df_words
n <- nrow(df_words)
cat("Number of words: ", n)
Friday, April 7, 2023
A more interesting pictorial numerical puzzle
I am getting tired of these little pictorial numerical puzzles with the four equations, like one where three
chickens equals 60, one chicken plus two plates of two eggs per plate equals 26, and so on, until
the final equation is to evaluate some mathematical expression involving chickens, eggs, and bananas.

The solution generally requires that you remember the PEMDAS (in the US, or BODMAS elsewhere) rules for order of operations especially that multiplication takes precedence over addition, and also that you carefully count the number of eggs and number of bananas. I get 36.
OK, let me try to create a more interesting pictorial puzzle.
Mathematicians agree on the PEMDAS rules, although there are many situations that PEMDAS doesn't handle. Perhaps the most common is the unary minus operator as in -32. It is unary because unlike subtraction that has two operands, the unary operator only has one. I think mathematicians would like to see the unary operator as changing the sign of the argument, so that -32 equals -9, although some software, most notably Excel, merrily calculate this as +9.
I don't believe there is a single authority for all the order of operations cases. For example, Excel, Google Search, and Wolfram Alpha do not always agree. I bet there are some pretty smart people in those companies.
Nowadays I am doing my fun calculations in the R computer language, so for the remainder of this post I will require R as the authority.
So here is my attempt at a more interesting problem, but remember, you have to use the order of operation precedence rules of R: (Let me add the link to the first item: https://www.facebook.com/watch/?v=10158293605695705 )
 |
Do you want to try it before I reveal the R code?
The R code is:
apple <- 1
banana <- 2
kiwi <- 3
lemon <- 4
peach <- banana + lemon
pear <- banana^banana^kiwi # 2^(2^3) = 256
pineapple <- (pear - banana) %% kiwi^2 * lemon # (254 %% 9) * 4 = 2 * 4 = 8
strawberry <- pineapple / peach * peach # 8; no obelus in R
kiwi <- c(lemon, pineapple, strawberry)
watermelon <- kiwi[kiwi == lemon | kiwi == pineapple & kiwi == strawberry]
# watermelon <- (lemon V pineapple ∧ strawberry) # 4 V (8 & 8) = 4, 8
The ordering rules of R include:
- Modular arithmetic is at the same level as multiplication: a mod b * c is (a mod b) *c
- The obelus does not appear in R but is just a division symbol: a ÷ b * c = (a / b) * c
- Repeated exponentiation goes right to left: a ^ b ^ c = a^(b^c); lots of disagreement outside R on this one
- Logical AND preceds logical OR
Monday, March 27, 2023
There's a black hole in the number line
The government doesn't want you to know about this, but I have discovered it and I will share this with a few close friends: There is a black hole in the number line, and it's at number 4. Every word in the English language will eventually fall into it and can't get out of it. As an example, take the word mathematical.
As an example, take the word mathematical. Try a few more words. Try words as long as you like. Try morphophonemically, which has 18 letters. I have done exhaustive research on this with R, and you will find every English word eventually falls into the black hole at 4 and can't get out. At this rate, there will be no words left!
Try a few more words. Try words as long as you like. Try morphophonemically, which has 18 letters. I have done exhaustive research on this with R, and you will find every English word eventually falls into the black hole at 4 and can't get out. At this rate, there will be no words left!

Mathematical has twelve letters.
Twelve has six letters.
Six has three letters.
Three has five letters.
Five has four letters.
Four has four letters.
Four has four letters, and now we entered this black hole at 4, and we can't get out of it!

Of course, this is an April Fool's Day prank.

Did you figure it out?
Here is some R code to test the word mathematical.
# Try word mathematical
library(broman)
x <- "mathematical"
y <- -99 # Initialize y
while(y != "four"){
y <- nchar(x)
y <- broman::spell_out(y, max_value = 20) # Spell out an integer as a word
print(c(x,y))
x <- y
}
Here is some R code to test ten random words.
# Try ten random words
set.seed(123)
words <- read.table("https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt")
original <- sample(words$V1, 10, replace = FALSE)
x <- original
rm(words) # free up memory
for (i in 1:10){
y <- vector()
y[1] <- "dummy"
for (j in 1:100){
c <- nchar(x[i])
y[j] <- spell_out(c, max_value = 20)
x[i] <- y[j]
if (y[j] == "four") {
break
}
}
cat(c(original[i], "\t", y), "\n")
}
Here is the code for the number line:
library(ggplot2)
df <- data.frame(x = c(1,2,3,4,5,6,7,8,9,10),
y = rep(0,10),
group = c("A","A","A","B","A","A","A","A","A","A"))
ggplot(df, aes(x = x, y = y)) +
geom_point(aes(color = group, size = ifelse(x == 4, 15, 15))) +
geom_hline(yintercept = 0, linetype = 1, color = "lightblue", size = 1) +
scale_x_continuous(limits = c(0, 11), expand = c(0, 0),
breaks = NULL, minor_breaks = NULL) +
scale_y_continuous(limits = c(-0.2, 0.2), expand = c(0, 0),
breaks = NULL, minor_breaks = NULL) +
scale_color_manual(values = c("red", "black")) +
ggtitle("THE BLACK HOLE AT NUMBER 4") +
theme_void() +
theme(legend.position = "none",
axis.line = element_blank(),
axis.text = element_blank(),
plot.title = element_text(color="black", size=14, face="bold")) +
geom_text(aes(x = x, y = -0.1, label = x), size = 5)
Saturday, February 25, 2023
These drinking glasses are too short!
These drinking glasses are too short!






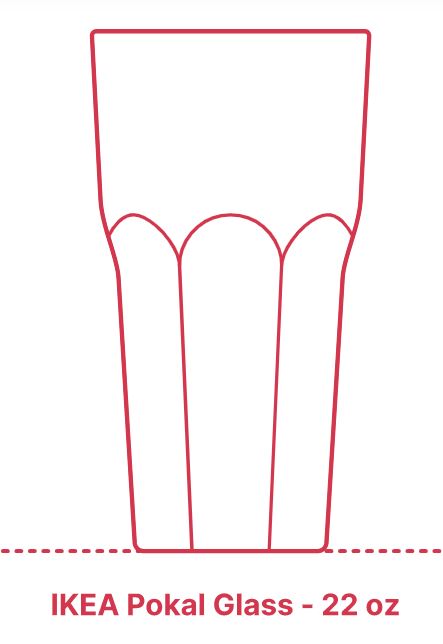
Some of my reinsurance and math teacher friends may remember that when I am out of town and having an adult beverage with friends, I have been known to stare at the drinking glass and say something like, "I don't mean to be rude, but the glasses are certainly short here. They are much shorter than what we have back home. In fact, they are so short, that I think that the circumference of the top of the glass is larger than the height."
Then there is generally a long pause as the group considers this. The reinsurance group may require some reminder of what circumference means.

Either group (unless they have heard this before, or unless they can guess that this is a setup) will likely disagree with me. I will reply that I am pretty sure about this, and I am willing to bet a dollar.
How do you measure this in a bar or restaurant? I use a paper or cloth napkin to measure the circumference from one end of the napkin to somewhere in the middle of the napkin, and then I use that length to compare to the height.
I have done this enough times so that I am nearly always right. Try it with your own drinking glasses. The only time it consistently fails is with champagne glasses.
Recently it occurred to me that there must be a website with a wide variety of glasses and their measurements, and I found Dimensions.com, https://www.dimensions.com . Dimensions.com is a database of drawings with standard measurements. Measurements are based on industry standards and averages and may differ among manufacturers and regions. Here is a sample of glasses with their images and measurements which are used here with permission, plus my calculations in the last three columns of the table. Volumes are in ounces, heights and diameters are in centimeters. The source is https://www.dimensions.com/collection/drinking-glasses and https://www.dimensions.com/collection/wine-glasses.





Here is some R code to do the calculations and to draw the above graph. Note that pi (lower case) is an inbuilt R constant whose value is approximately 3.141593. (Yes, I am well aware that π is an infinite, non-repeating decimal, and I believe R carries 16 decimal digits, but that is beyond the scope of this article.)
df <- data.frame(glass = c("Kalina10", "Pokal22", "Chardonnay", "XL Oversized","Cordial", "Shooter", "Champagne"),
volume = c(10, 22, 12.3, 25.36, 1.5, 2, 9),
height = c(11, 17.75, 19.8, 22.9, 15.9, 10.5, 23.5),
diameter = c(8, 9.5, 7.9, 10.8, 5.1, 4.13, 6.35))
df$circumference <- round(pi * df$diameter, 1)
df$larger <- ifelse(df$circumference > df$height, "Circumference", "Height")
df$c_to_h <- round(df$circumference / df$height, 1)
df
library(ggplot2)
ggplot(df, aes(x=factor(glass, level = c("Kalina10", "Pokal22", "Chardonnay", "XL Oversize","Cordial", "Shooter", "Champagne")), y=c_to_h, fill = glass, color="black")) +
geom_col(width = 1, position = position_dodge(1)) +
geom_hline(yintercept=1) +
ggtitle("Ratio of Circumference to Height by Glass") + xlab("Glass") + ylab("Ratio") +
theme(plot.title = element_text(face="bold", size=12)) +
theme(axis.text.x = element_text(face="bold", size=12)) +
theme(axis.text.y = element_text(size=12, face="bold")) +
theme(legend.position="none") +
scale_fill_manual("glass", values=c("red", "yellow", "blue", "green", "grey", "brown", "violet"))
I think the reason this is a good bet is that the mind can not easily compare a circular length to a linear length (I don't know if that is scientifically accurate), plus perhaps we look at the diameter but we forget we are comparing the height not to the diameter, but rather to π times the diameter.
Feel free to make this bet with your friends or your students. How about sharing 10% of your winnings with me as a commission?
Incidentally, a beverage can is approximately a right circular cylinder. (But not exactly; look at the top and bottom to see why.) Calculus students can derive that the cylinder with the largest volume for a given surface area (the surface area can be thought of as the rectangular area of the paper label around the entire can), has height equal to diameter. A typical 12 ounce soda can does not have height equal to diameter, but its circumference is greater than its height. A fun supermarket experiment is to examine different shaped cans (a soup can, a tuna fish can, etc.) to determine which meet the largest volume criterion.
To my reinsurance friends: I learned the circumference greater than height trick from Paul Hawksworth of M&G.
Sunday, February 12, 2023
Some different graph types in R
I don't know about you, but I get tired of seeing column charts and pie charts. It's not difficult to create a few more interesting chart types once in a while. Whether these are relevant for a particular audience and truly display your message is a different question.

I wanted a really small dataset to experiment in R, so I used numbers of days in office for US presidents who were assassinated. Students
of American history may want to pause reading this post and think about whether you can name the Presidents (and estimate the number of days), before continuing reading. Kennedy and Lincoln are most well-known, but there were others.
I decided I wanted a column chart with images on the x-axis, a wordcloud with the font size proportional to the number of days, a lolliplot chart which is a variation of a column chart but with a line instead of a bar and a dot at the end, and a donut chart which is a variation of a pie chart but where your eye focuses on the length of the arc rather than on the area of the sector.
The first chart requires images. I grabbed the images I needed (hopefully these are either old or Federal and therefore not subject to copyright prohibitions) and saved them as png files so they could be read with a readPNG from the png package.
Of course there are many more chart types that are beyond the scope of this blog post. One reference is Top 50 ggplot2 Visualizations - The Master List (With Full R Code). A very cool chart type is the radar chart which you can see at How to Create Radar Charts in R (With Examples).
Here is my output (click to enlarge) and my R code:

setwd("C:/Users/ ... ")
suppressMessages(library(dplyr))
suppressMessages(library(ggplot2))
library(png)
library(ggtext)
df <- data.frame(President = c("Lincoln", "Garfield", "McKinley", "Kennedy"),
Days_in_office = c(1503,199,1654,1036) )
# column chart with images on x-axis
p <- df %>%
ggplot() +
geom_col(mapping=aes(President, y=Days_in_office, fill=President)) +
scale_fill_manual(values=c("blue", "yellow", "red", "black")) +
labs(title="Axis Labels as Images") +
theme(plot.title = element_text(hjust = .5))
garfield <- readPNG("garfield.png")
kennedy <- readPNG("kennedy.png")
lincoln <- readPNG("lincoln.png")
mckinley <- readPNG("mckinley.png")
# in the following labels statement, please replace q with <, and replace z with >
labels <-
c("qimg src='garfield.png', width='35' /z","qimg src='kennedy.png', width='35' /z","qimg src='lincoln.png', width='35' /z","qimg src='mckinley.png', width='40', height='42' /z")
p <- p +
scale_x_discrete(labels = labels) +
theme(axis.text.x = ggtext::element_markdown())
p # takes a moment to draw
# ==============================================================
suppressMessages(library(wordcloud))
df %>% with(wordcloud(words=President, freq=Days_in_office, random.order=FALSE, random.color=FALSE, rot.per = 0,
colors = c("blue","black", "red")))
# =====================================================
# lolliplot plot
df %>%
ggplot() +
geom_segment(mapping=aes(x=President, xend=President, y=0, yend=Days_in_office), color=c("blue", "yellow", "red", "black") ) +
geom_point(aes(x=President, y=Days_in_office), size=4, color=c("blue", "yellow", "red", "black") ) +
ylab("Days_in_office") +
theme(axis.text = element_text(face="bold")) +
theme(text = element_text(size =16)) +
labs(title="Lolliplot Plot") +
theme(plot.title = element_text(hjust = .5))
df
# ===========================================================
# donut plot
donut <- br="" df="">
donut$fraction = donut$Days_in_office / sum(donut$Days_in_office)
# Compute the cumulative percentages (top of each rectangle)
donut$ymax = cumsum(donut$fraction)
# Compute the bottom of each rectangle
donut$ymin = c(0, head(donut$ymax, n=-1))
# Compute label position
donut$labelPosition <- 2="" br="" donut="" ymax="" ymin="">
# Create label
donut$label <- ays_in_office="" br="" donut="" n="" paste0="" resident="" value:="">
# Make the plot
ggplot(donut, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=President)) +
geom_rect() +
geom_label( x=3.5, aes(y=labelPosition, label=label), size=6) +
scale_fill_brewer(palette=4) +
coord_polar(theta="y") +
xlim(c(2, 4)) +
theme_void() +
theme(legend.position = "none") +
theme(text = element_text(size =16)) +
labs(title="Donut Plot") +
theme(plot.title = element_text(hjust = .5))
Subscribe to:
Posts (Atom)