Some of my reinsurance and math teacher friends may remember that when I am out of town and having an adult beverage with friends, I have been known to stare at the drinking glass and say something like, "I don't mean to be rude, but the glasses are certainly short here. They are much shorter than what we have back home. In fact, they are so short, that I think that the circumference of the top of the glass is larger than the height."
Then there is generally a long pause as the group considers this. The reinsurance group may require some reminder of what circumference means.

Either group (unless they have heard this before, or unless they can guess that this is a setup) will likely disagree with me. I will reply that I am pretty sure about this, and I am willing to bet a dollar.
How do you measure this in a bar or restaurant? I use a paper or cloth napkin to measure the circumference from one end of the napkin to somewhere in the middle of the napkin, and then I use that length to compare to the height.
I have done this enough times so that I am nearly always right. Try it with your own drinking glasses. The only time it consistently fails is with champagne glasses.
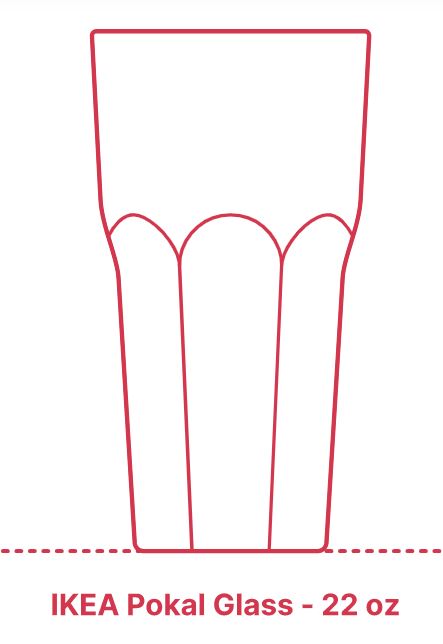
Recently it occurred to me that there must be a website with a wide variety of glasses and their measurements, and I found Dimensions.com, https://www.dimensions.com . Dimensions.com is a database of drawings with standard measurements. Measurements are based on industry standards and averages and may differ among manufacturers and regions. Here is a sample of glasses with their images and measurements which are used here with permission, plus my calculations in the last three columns of the table. Volumes are in ounces, heights and diameters are in centimeters. The source is https://www.dimensions.com/collection/drinking-glasses and https://www.dimensions.com/collection/wine-glasses.





Here is some R code to do the calculations and to draw the above graph. Note that pi (lower case) is an inbuilt R constant whose value is approximately 3.141593. (Yes, I am well aware that π is an infinite, non-repeating decimal, and I believe R carries 16 decimal digits, but that is beyond the scope of this article.)
df <- data.frame(glass = c("Kalina10", "Pokal22", "Chardonnay", "XL Oversized","Cordial", "Shooter", "Champagne"),
volume = c(10, 22, 12.3, 25.36, 1.5, 2, 9),
height = c(11, 17.75, 19.8, 22.9, 15.9, 10.5, 23.5),
diameter = c(8, 9.5, 7.9, 10.8, 5.1, 4.13, 6.35))
df$circumference <- round(pi * df$diameter, 1)
df$larger <- ifelse(df$circumference > df$height, "Circumference", "Height")
df$c_to_h <- round(df$circumference / df$height, 1)
df
library(ggplot2)
ggplot(df, aes(x=factor(glass, level = c("Kalina10", "Pokal22", "Chardonnay", "XL Oversize","Cordial", "Shooter", "Champagne")), y=c_to_h, fill = glass, color="black")) +
geom_col(width = 1, position = position_dodge(1)) +
geom_hline(yintercept=1) +
ggtitle("Ratio of Circumference to Height by Glass") + xlab("Glass") + ylab("Ratio") +
theme(plot.title = element_text(face="bold", size=12)) +
theme(axis.text.x = element_text(face="bold", size=12)) +
theme(axis.text.y = element_text(size=12, face="bold")) +
theme(legend.position="none") +
scale_fill_manual("glass", values=c("red", "yellow", "blue", "green", "grey", "brown", "violet"))
I think the reason this is a good bet is that the mind can not easily compare a circular length to a linear length (I don't know if that is scientifically accurate), plus perhaps we look at the diameter but we forget we are comparing the height not to the diameter, but rather to π times the diameter.
Feel free to make this bet with your friends or your students. How about sharing 10% of your winnings with me as a commission?
Incidentally, a beverage can is approximately a right circular cylinder. (But not exactly; look at the top and bottom to see why.) Calculus students can derive that the cylinder with the largest volume for a given surface area (the surface area can be thought of as the rectangular area of the paper label around the entire can), has height equal to diameter. A typical 12 ounce soda can does not have height equal to diameter, but its circumference is greater than its height. A fun supermarket experiment is to examine different shaped cans (a soup can, a tuna fish can, etc.) to determine which meet the largest volume criterion.
To my reinsurance friends: I learned the circumference greater than height trick from Paul Hawksworth of M&G.